Last Updated on 2022年5月23日
今回行うこと
今回は下記を行いたいと思います。
・前回取得したHTMLをParserして中身を確認する
・Yahooの画面上部に存在する文字列の取得
↓ 下記赤枠の文字列取得です。

Yahoo スクレイピングコード
今回のコードは以下になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
function Gas_WebScraping02() { // YahooのURLを指定 let get_url = "https://www.yahoo.co.jp/"; // getContentTest()のデフォルト指定は(utf-8)になるので省略 let get_html = UrlFetchApp.fetch(get_url).getContentText(); // Parserする前の中身を確認 console.log("get_html = " + get_html) // 複数の文字列を取得するための配列を宣言 let other = [] // 画面上部のカテゴリー(トラベル~メール)を取得 other = Parser.data(get_html).from('oLvk9L5Yk-9JOuzi-OHW5').to('</span>').iterate(); // Parser後の中身を確認 console.log("other = " + other) // 取得した配列の数だけループを回す for(let x = 0; x < other.length; x++){ // 正規表現なしの状態 console.log("other1 = " + other[x]); // 開始:" 終了:> までを空白にする console.log("other2 = " + other[x].replace(/".*>/,"")); } } |
解説
途中までは前回と同じですね、↓で「Parser」を行っています。
|
1 2 |
// 画面上部のカテゴリー(トラベル~メール)を取得 other = Parser.data(get_html).from('oLvk9L5Yk-9JOuzi-OHW5').to('</span>').iterate(); |
from:に検索を開始する文字列
to:終了の文字列
をそれぞれ記入します。
↓ From:これはYahooページの下記部分です。全部で6件ヒットしています。
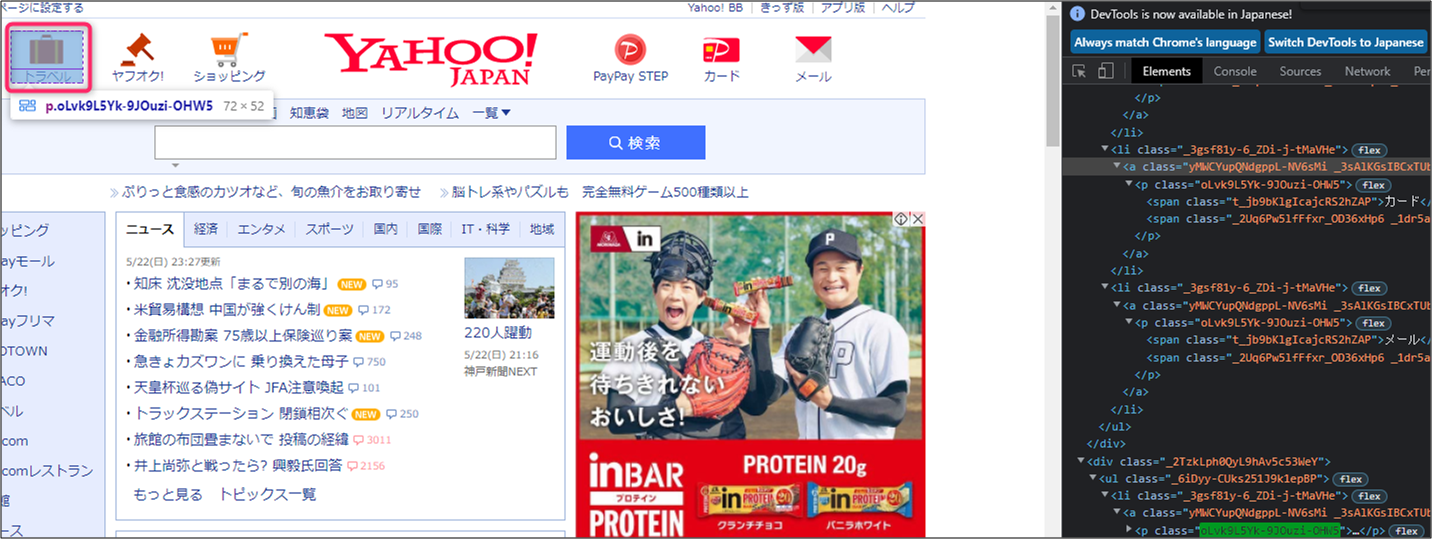
↓ to:続いてtoへ。見えづらいですが、トラベルの部分です。
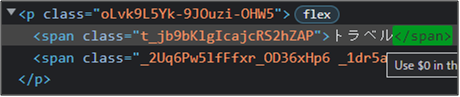
変数「other」へ「Parser」後の値を格納しています。
出力すると以下が表示されています。
欲しかった値は取得できているようですね!

欲しい文字列は
・PayPay STEP、カード、メール、トラベル、ヤフオク!、ショッピング
なので、forで余計な文字列を削除します。
|
1 2 3 4 5 6 7 8 9 10 |
// 取得した配列の数だけループを回す for(let x = 0; x < other.length; x++){ // 正規表現なしの状態 console.log("other1 = " + other[x]); // 開始:" 終了:> までを空白にする console.log("other2 = " + other[x].replace(/".*>/,"")); } |
変数「other1 」をconsoleへと出力し確認してみると、
|
1 2 |
<span class="t_jb9bKlgIcajcRS2hZAP">PayPay STEP <span class="t_jb9bKlgIcajcRS2hZAP">カード |
が出力されています。
「">」までが毎回不要ですね!
replace関数を使用し、正規表現を用いて「/".*>/,""」を行います。
正規表現の条件は「"始まりで、>を見つけたら、該当部分を空白にする。」
という意味です。
変数「other2」へ正規表現後を行った内容を格納しているので出力してみます。
・other2 = PayPay STEP
・other2 = カード
として無事に欲しかった値が格納されていることを確認できました!
Pythonと比べると簡単に出来るような、逆に難しいような、、、
これからも学習が必要になりそうです。
今回は以上になります。
最後までお読みいただきありがとうございました!






