Last Updated on 2025年7月28日
検索結果をCSVへ!
前回スクレイピングした内容をテキストへ保存しました!
CSVへの保存も簡単に行えます。
前回のソースコードを少し綺麗に?しながらCSVファイルへ落とし込みたいと思います。
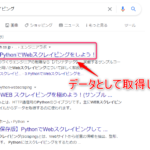
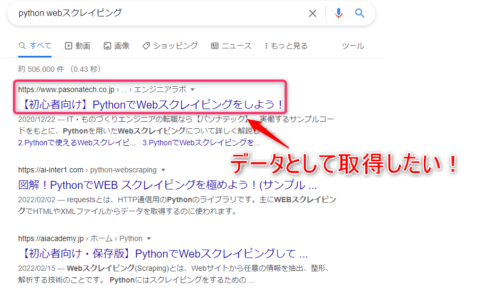
【イメージ】
↓ の検索結果を
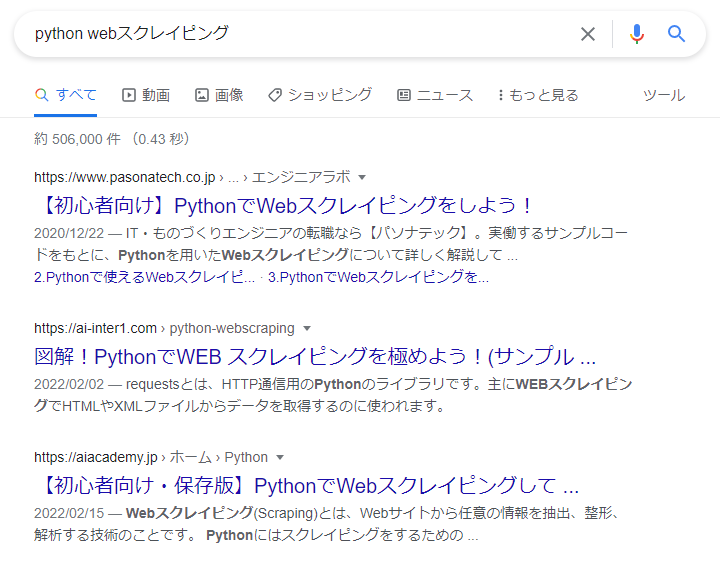
↓ のようなCSV形式へ出力!
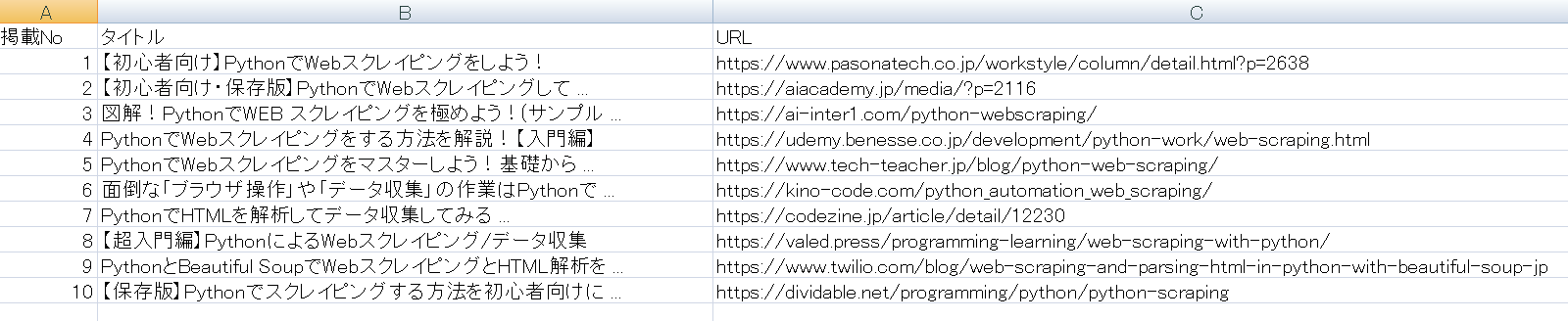
とはいっても、
ソースコードの9割は前回と同じです!
テキスト形式をCSVファイルへ書き込むように変更しました。
後はそれぞれ関数に纏めて小奇麗にした感じですね。
実行して頂くと.pyファイルと同じディレクトリ上に「Googleサーチ.csv」というファイルが作成されると思います。
ソースコードは以下になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
# BeautifulSoup関連 from bs4 import BeautifulSoup import time # selenium関連 from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.chrome.options import Options # CSV関連 import csv import os # /*------------------------------------------ # ドライバーの準備 / Webサイト取得(Selenium) # --------------------------------------------*/ def get_driver(): # ヘッドレスモードを付与 options = Options() options.add_argument("--headless") driver = webdriver.Chrome(ChromeDriverManager().install(),options=options) # 上位から何件までのサイトを抽出するか指定する pages_num = 10 + 1 # キーワード key_word = 'python Webスクレイピング' # Google検索で「python Webスクレイピング」の結果を格納する url = 'https://www.google.com/search?num={}&q={}'.format(pages_num,key_word) # SeleniumでURLを起動する driver.get(url) time.sleep(2) return driver # /*------------------------------------------ # Webサイトからスクレイピング(BeautifulSoup) # --------------------------------------------*/ def get_data_from_source(driver): # WebサイトのHTMLデータをBeautifulSoupで解析する soup = BeautifulSoup(driver.page_source,'html.parser') # 検索結果のまとまり page_titles = soup.find_all(class_="NJo7tc Z26q7c jGGQ5e") title_detail = [] i = 0 # 1件別でタイトルとURLを取得する for page_title in page_titles: title = page_title.h3.text url = page_title.find("a").get("href").replace('/url?q=','') i = i + 1 # 取得した内容をリスト変数へ書き込む title_detail.append([i,title,url]) return title_detail # /*------------------------------------------ # CSVファイルの処理 # --------------------------------------------*/ def save_csv(data_detail): # 相対パスで実行ファイルのフォルダ内のCSVフォルダへCSVを作成して格納する csv_path = os.getcwd() csv_file_name = "Googleサーチ.csv" # ファイルを格納する場所に、ファイル名を教えている csv_path = os.path.join(csv_path,csv_file_name) with open(csv_path, 'w') as file: writer = csv.writer(file, lineterminator='\n') csv_header = ["掲載No","タイトル","URL"] writer.writerow(csv_header) writer.writerows(data_detail) # /*------------------------------------------ # 処理開始 # --------------------------------------------*/ if __name__ == "__main__": # ブラウザのdriver取得 driver = get_driver() # Webサイトからデータ抽出 data_detail = get_data_from_source(driver) # 抽出したデータを渡してCSV形式で保存を行う save_csv(data_detail) |
「Googleサーチ.csv」というファイル名をベタ書きしているので
実際には「datetime」などを使用してファイル名に日付も加えると
より良いかと思いますー。
では追加した箇所の解説です。
処理開始
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# /*------------------------------------------ # 処理開始 # --------------------------------------------*/ if __name__ == "__main__": # ブラウザのdriver取得 driver = get_driver() # Webサイトからデータ抽出 data_detail = get_data_from_source(driver) # 抽出したデータを渡してCSV形式で保存を行う save_csv(data_detail) |
それぞれを関数に纏めただけですが、こっちの方が後々見返す時に分かり易いですね。
「get_driver()」
→ Webサイトの表示をして、
戻り値をdriverへ格納しています。
「get_data_from_source(driver)」
→ Web上に表示されているサイトを解析し、
appendしたリストを「data_detail 」へ返しています。
「data_detail 」
→ スクレイピングの結果が入っていますので
そのデータを「save_csv(data_detail)」で渡して、
そこでCSV処理を行っています。
続いてCSV処理のお話です。
CSV処理
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# /*------------------------------------------ # CSVファイルの処理 # --------------------------------------------*/ def save_csv(data_detail): # 相対パスで実行ファイルのフォルダ内のCSVフォルダへCSVを作成して格納する csv_path = os.getcwd() csv_file_name = "Googleサーチ.csv" # ファイルを格納する場所に、ファイル名を教えている csv_path = os.path.join(csv_path,csv_file_name) with open(csv_path, 'w') as file: writer = csv.writer(file, lineterminator='\n') csv_header = ["掲載No","タイトル","URL"] writer.writerow(csv_header) writer.writerows(data_detail) |
CSVファイルへ書き込みを行っています。
csv_path = os.getcwd()
→ 現在pyファイルを実行している階層をcsv_path へ渡しています。
csv_file_name = "Googleサーチ.csv"
→ そのままの意味ですね!
直接文字入力しても良いのですが、変数へ格納しています。
csv_path = os.path.join(csv_path,csv_file_name)
→ 現在の階層へ、Googleサーチ.csvというファイル名で書き込む準備。
writer = csv.writer(file, lineterminator='\n')
→ lineterminatorで改行コードを指定しています。
csv_header = ["掲載No","タイトル","URL"]
writer.writerow(csv_header)
→ CSVファイルの1行目のヘッダーを決めています。
writerowなのは、出力が1行しかないためです。
writer.writerows(data_detail)
→ 格納されているリストのインデックスで改行して書き込みを行っています。
改行するためのコードは「lineterminator」で「\n」を指定しているので、
無事に改行が行えます!
以上となります。
今回も最後までお読み頂き、ありがとうございました!