Googleの検索結果を別タブ(javascript)で開きながらフルサイズのスクリーンショットを取得する
行いたいこと 前回Googleの検索結果を別タブで開いていきました。 今回は別タブで開いた画面内で上から下までのスクリーンショット を取得したいと思います。 ↓実行結果イメージ コード [crayon-69d46c97c…
 Python
Python
行いたいこと 前回Googleの検索結果を別タブで開いていきました。 今回は別タブで開いた画面内で上から下までのスクリーンショット を取得したいと思います。 ↓実行結果イメージ コード [crayon-69d46c97c…
Python
行いたいこと いらすとやの画像より、 複数の画像を一気にダウンロードする。 ということを試してみたいと思います。 例えば以下のようなページの場合、サッカーを行っている画像だけではなく 表示されている全ての画像ファイルが対…
 Python
Python
XPath Helperとは XPath Helperは簡単にxpathを取得出来るChromeのツール。 らしいです。 これまでxpathをコピーする際は、 ・右クリック > 検証 > コピー > xpathをコピー …
 Python
Python
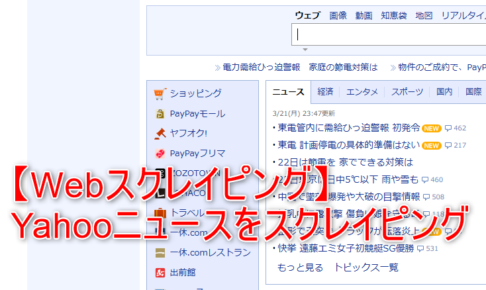
Yahooニュースのスクレイピング 今回はYahooニュースの「ニュース」タブの部分の取得、 それぞれのニュースの詳細(記事全文を読む)の部分を SeleniumとBeautifulSoupを使用して取得してみたいと思い…
 Python
Python
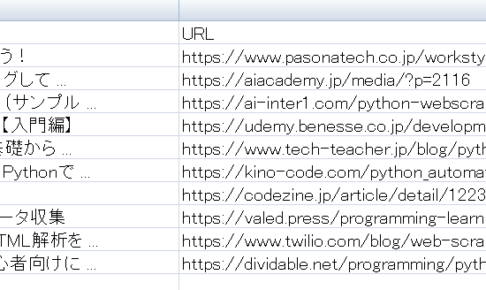
検索結果をCSVへ! 前回スクレイピングした内容をテキストへ保存しました! CSVへの保存も簡単に行えます。 前回のソースコードを少し綺麗に?しながらCSVファイルへ落とし込みたいと思います。 【イメージ】 ↓ の検索結…
 Python
Python
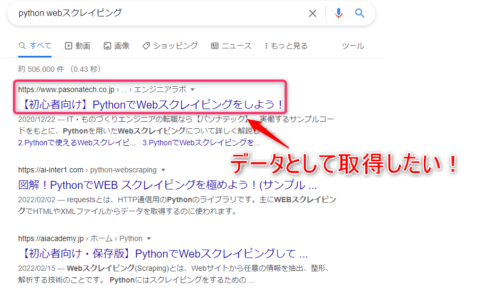
検索結果をスクレイピング 前回はメルカリのスクレイピングをSeleniumで行いました。 今回は「BeautifulSoup」を使ってみたいということで、 メルカリと比べると大分短いソースコードになりますが、 ・Goog…
 Python
Python
classが見つからない! 前回は「Selenium」のみのWebスクレイピングを行ったので 今回は「BeautifulSoup」を使用したいと思い、 Googleの検索結果で以下のような1件ずつの タイトルとURLを取…
 Python
Python
Webスクレイピングとは この記事をご覧になってくださる方は既にご存じかと思いますが、 Webスクレイピングとは、Webサイトから自分が必要な情報を収集できる。 ことだと考えています(ザックリ) 例えば ・グーグルの検索…