Last Updated on 2025年7月28日
Yahooニュースのスクレイピング
今回はYahooニュースの「ニュース」タブの部分の取得、
それぞれのニュースの詳細(記事全文を読む)の部分を
SeleniumとBeautifulSoupを使用して取得してみたいと思います。
今回の記事を作成するにあたり、こちらのサイトをご参考にさせていただきました。
取得する内容
以下の順番でコーディングしたいと思います。
1. Yahooニュースの「ニュース」タブ、タイトルを取得
2. 取得したタイトル1つ1つへアクセスする
3. アクセスした記事内容の「記事全文を読む」をクリックする
4. 表示された本文を取得
5. タイトル、本文、URLをリストへ格納する
6. 格納したリストをCSVへ書き込む
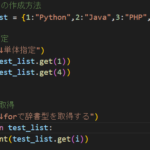
1.Yahooニュースの「ニュース」タブ、タイトルを取得
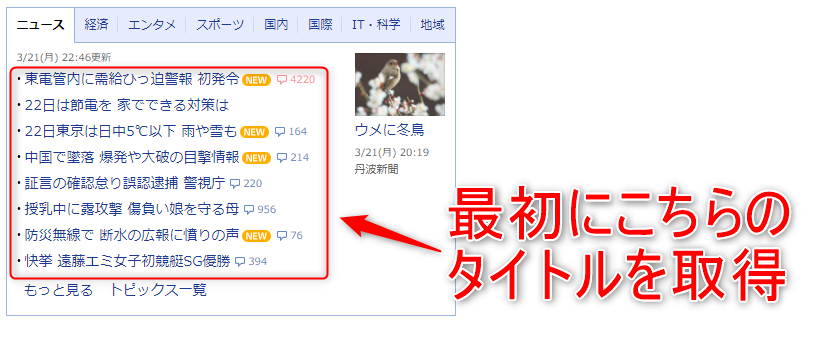
2,3. アクセスした記事内容の「記事全文を読む」をクリックする
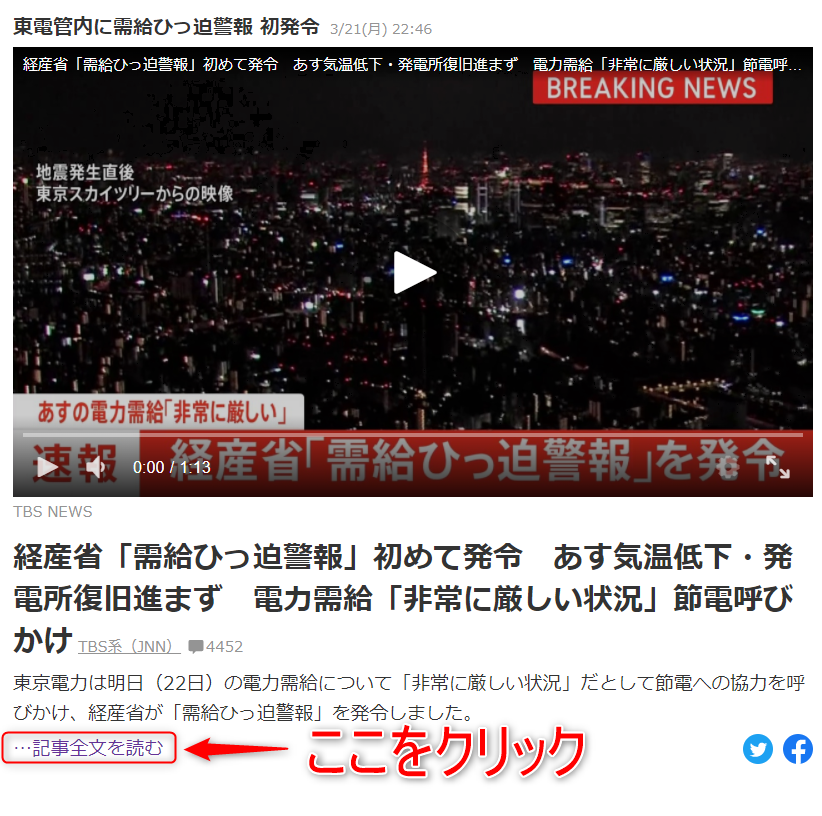
4. 表示された本文を取得
5,6 タイトル、本文、URLをリストへ格納し、CSVへ出力する
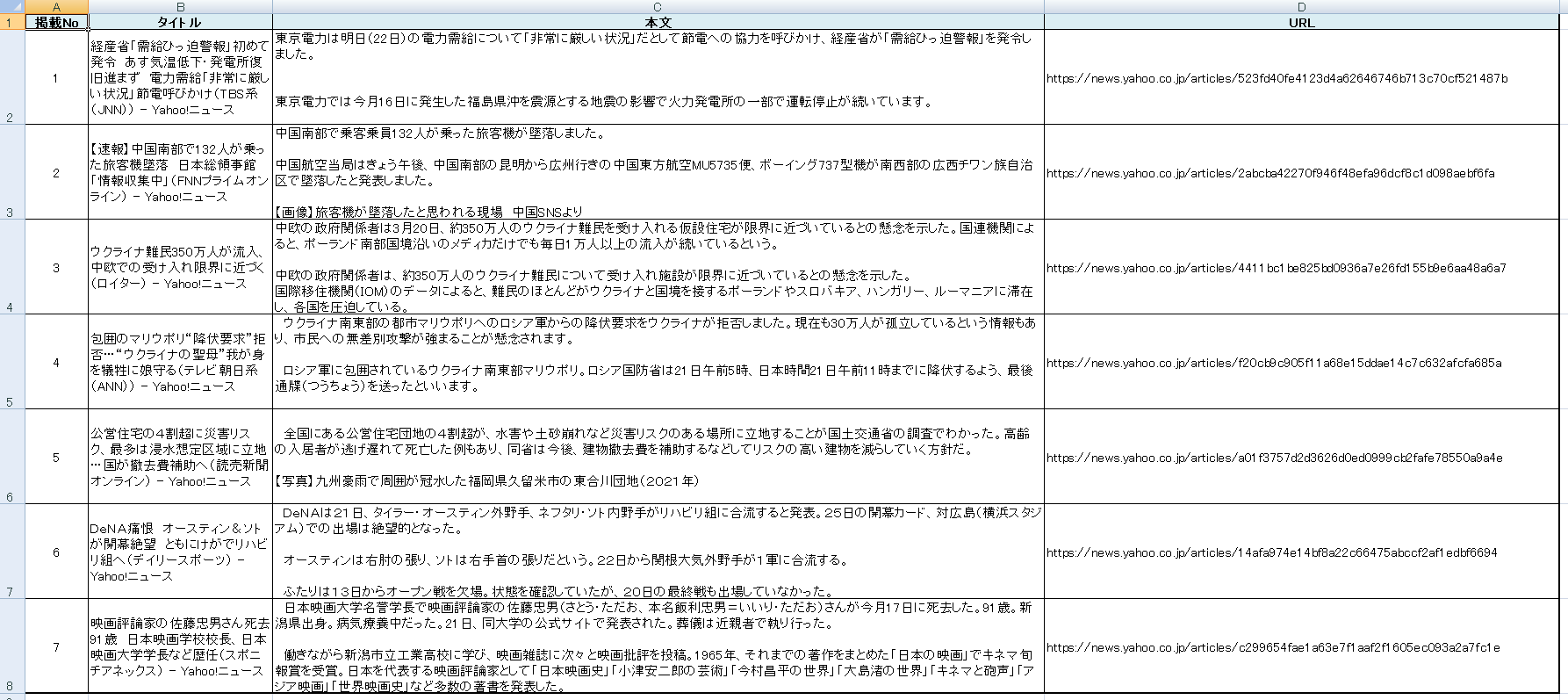
最終的に、このようなCSVファイルを取得します。
※書き込み直後は書式設定されていません。
ソースコード
実行するとヘッドレスモード(ブラウザが起動しない)で実行されます。
ブラウザの動きを見ながら実行したい場合は、
24行目の「driver = webdriver.Chrome(ChromeDriverManager().install(),options=options)」
をコメントアウトして、
25行目の「# driver = webdriver.Chrome(ChromeDriverManager().install())」
のコメントアウトを外してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 |
from bs4 import BeautifulSoup import re # selenium関連 from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.chrome.options import Options import time # CSV関連 import csv import os # /*------------------------------------------ # ドライバーの準備 / Webサイト表示 # --------------------------------------------*/ def get_driver(): # ヘッドレスモードを付与 options = Options() options.add_argument("--headless") driver = webdriver.Chrome(ChromeDriverManager().install(),options=options) # driver = webdriver.Chrome(ChromeDriverManager().install()) # 今回のスクレイピング対象サイト(Yahoo) url = 'https://www.yahoo.co.jp/' # SeleniumでURLを起動する driver.get(url) time.sleep(2) return driver # /*------------------------------------------ # YahooNewsのスクレイピング # --------------------------------------------*/ def get_data_from_source(driver): # 表示しているWebサイトのHTMLデータをBeautifulSoupで解析する soup = BeautifulSoup(driver.page_source,'html.parser') # URLに news.yahoo.co.jp/pickup が含まれるものを抽出する。 news_list = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup")) # 見出しのURLをリスト形式にして返す news_link_lists = [data.attrs["href"] for data in news_list] # 後でCSVファイルで使用する変数 title_detail = [] i = 0 # 見出しのYahooNewsをリストで持っているので、1件ずつ確認する for news_link in news_link_lists: # YahooNewsの見出し記事を1つずつクリックする driver.get(news_link) time.sleep(2) # 記事全文を読むボタンの要素 search_btn = driver.find_element_by_xpath('//*[@id="uamods-pickup"]/div[2]/div/p/a') # 記事全文を読むボタンをクリック search_btn.click() time.sleep(2) # 記事全文を読むボタンをクリックした後の画面 # 取得した要約ページをBeautifulSoupで解析できるようにする summary_soup = BeautifulSoup(driver.page_source,'html.parser') # class属性の中で「Direct」が含まれる行(ニュースの本文)を取得する detail = summary_soup.find(class_=re.compile("Direct")) # metaタグの中からURLを探す detail_Url = summary_soup.find_all('meta',content=re.compile("https://news.yahoo.co.jp/articles")) # 取得した内容をリスト変数へ書き込む if detail is not None: i = i + 1 title_detail.append([i,summary_soup.title.text,detail.text,detail_Url[0]["content"]]) return title_detail # /*------------------------------------------ # CSVファイルの処理 # --------------------------------------------*/ def save_csv(data_detail): # 相対パスで実行ファイルのフォルダ内のCSVフォルダへCSVを作成して格納する csv_path = os.getcwd() csv_file_name = "YahooNews.csv" # ファイルを格納する場所に、ファイル名を教えている csv_path = os.path.join(csv_path,csv_file_name) with open(csv_path, 'w') as file: writer = csv.writer(file, lineterminator='\n') csv_header = ["掲載No","タイトル","本文","URL"] writer.writerow(csv_header) writer.writerows(data_detail) # /*------------------------------------------ # 処理開始 # --------------------------------------------*/ if __name__ == "__main__": # ブラウザのdriver取得 driver = get_driver() # Webサイトからデータ抽出 data_detail = get_data_from_source(driver) # 抽出したデータを渡してCSV形式で保存を行う save_csv(data_detail) |
ソースコード解説
最初はmainの処理から走り出します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# /*------------------------------------------ # 処理開始 # --------------------------------------------*/ if __name__ == "__main__": # ブラウザのdriver取得 driver = get_driver() # Webサイトからデータ抽出 data_detail = get_data_from_source(driver) # 抽出したデータを渡してCSV形式で保存を行う save_csv(data_detail) |
get_driver()関数を呼び出して
yahooのトップページ表示。
返ってきたdriverを元にBeautifulSoupで解析を行い、
最後にCSVへ書き込み。
となります。
続いてget_driver関数が呼び出されます。
「https://www.yahoo.co.jp/」へWebブラウザでアクセスして
トップページを表示しているだけです。
URLの起動はChromeDriverを使用して、Seleniumを起動させています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# /*------------------------------------------ # ドライバーの準備 / Webサイト表示 # --------------------------------------------*/ def get_driver(): # ヘッドレスモードを付与 options = Options() options.add_argument("--headless") driver = webdriver.Chrome(ChromeDriverManager().install(),options=options) # driver = webdriver.Chrome(ChromeDriverManager().install()) # 今回のスクレイピング対象サイト(Yahoo) url = 'https://www.yahoo.co.jp/' # SeleniumでURLを起動する driver.get(url) time.sleep(2) return driver |
続いてget_data_from_source(driver)が呼び出されます。
ここが処理のメイン部分ですね。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
# /*------------------------------------------ # YahooNewsのスクレイピング # --------------------------------------------*/ def get_data_from_source(driver): # 表示しているWebサイトのHTMLデータをBeautifulSoupで解析する soup = BeautifulSoup(driver.page_source,'html.parser') # URLに news.yahoo.co.jp/pickup が含まれるものを抽出する。 news_list = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup")) # 見出しのURLをリスト形式にして返す news_link_lists = [data.attrs["href"] for data in news_list] # 後でCSVファイルで使用する変数 title_detail = [] i = 0 # 見出しのYahooNewsをリストで持っているので、1件ずつ確認する for news_link in news_link_lists: # YahooNewsの見出し記事を1つずつクリックする driver.get(news_link) time.sleep(2) # 記事全文を読むボタンの要素 search_btn = driver.find_element_by_xpath('//*[@id="uamods-pickup"]/div[2]/div/p/a') # 記事全文を読むボタンをクリック search_btn.click() time.sleep(2) # 記事全文を読むボタンをクリックした後の画面 # 取得した要約ページをBeautifulSoupで解析できるようにする summary_soup = BeautifulSoup(driver.page_source,'html.parser') # class属性の中で「Direct」が含まれる行(ニュースの本文)を取得する detail = summary_soup.find(class_=re.compile("Direct")) detail_Url = summary_soup.find_all('meta',content=re.compile("https://news.yahoo.co.jp/articles")) # 取得した内容をリスト変数へ書き込む if detail is not None: i = i + 1 title_detail.append([i,summary_soup.title.text,detail.text,detail_Url[0]["content"]]) return title_detail |
まずWebサイトはYahooのトップページを開いている状態なので
BeautifulSoupで解析を行います。
# 表示しているWebサイトのHTMLデータをBeautifulSoupで解析する
soup = BeautifulSoup(driver.page_source,'html.parser')
次にニュースタブのタイトルを取得します。
ニュースタブのタイトルには「news.yahoo.co.jp/pickup」が
含まれている。という法則があります。
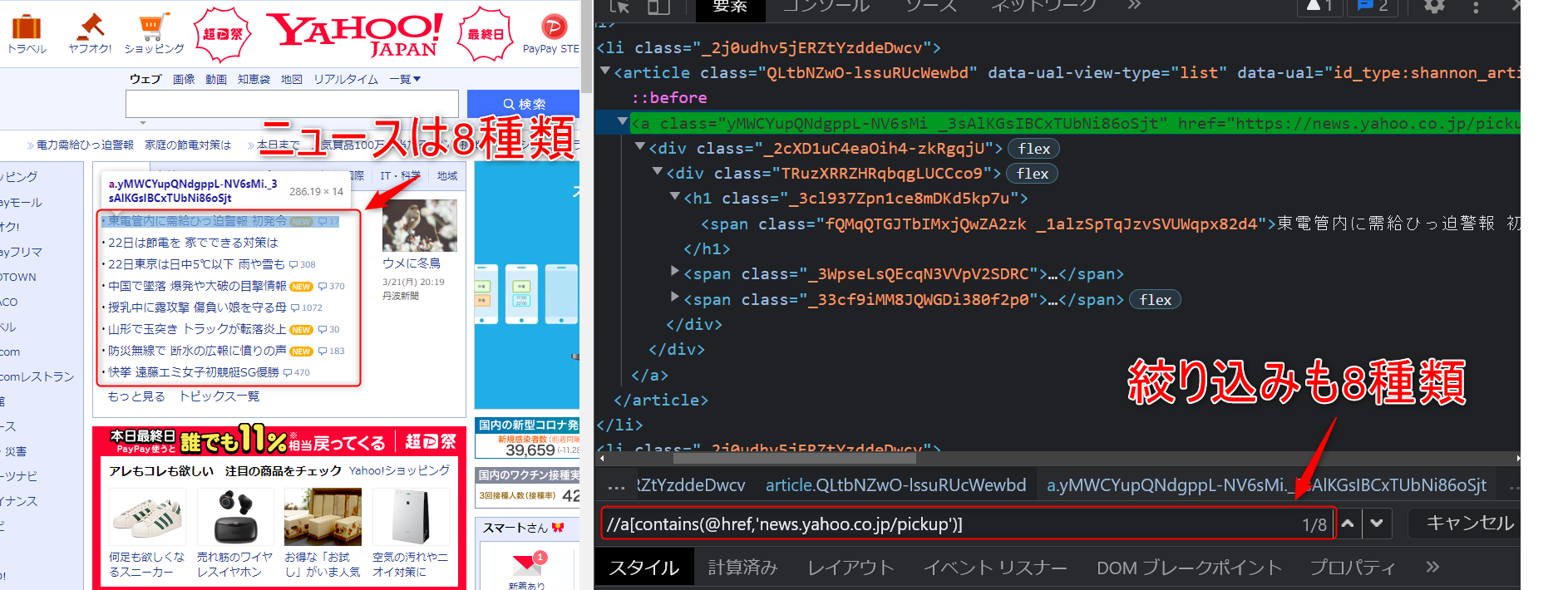
以下を行ってnews_list 変数に絞り込んだ結果を格納します。
# URLに news.yahoo.co.jp/pickup が含まれるものを抽出する。
news_list = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
この時点でnews_list 変数をデバッグすると
8つ格納されていることが分かります。
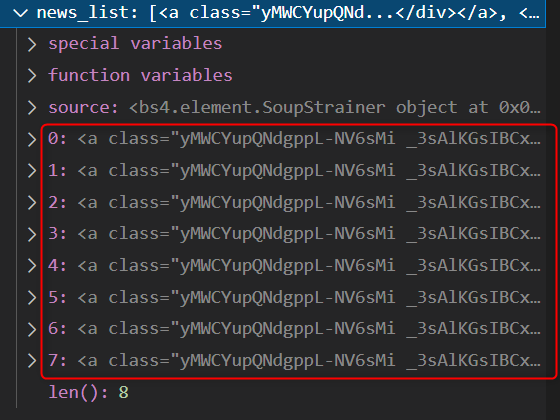
これでタイトル部分の要素の取得が完了しました!
現在格納しているnews_list 変数からURL部分を取り出します。
URL部分を取り出したら、詳細ページへ遷移可能になるためです。
以下でURL部分を取り出しています。
# 見出しのURLをリスト形式にして返す
news_link_lists = [data.attrs["href"] for data in news_list]
ではこの時点でnews_link_lists変数を確認してみましょう!
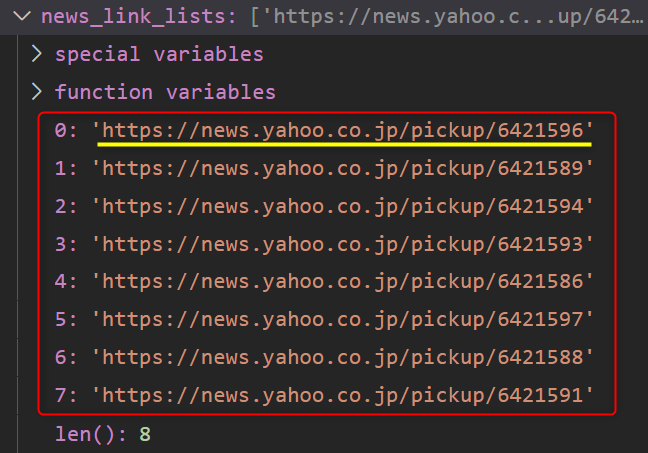
上手く取得出来ているみたいですね。
試しに黄色の線を引いたURLへアクセスしてみます。
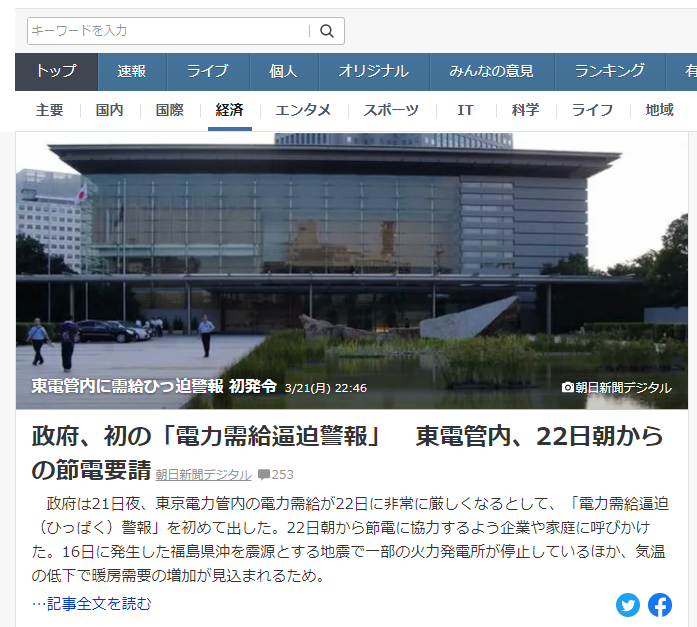
リンク先も問題ないようです。
では「記事全文を読む」をクリックして、詳細ページへと移動しましょう。
ここでSeleniumの出番ですね。
# 記事全文を読むボタンの要素
search_btn = driver.find_element_by_xpath('//*[@id="uamods-pickup"]/div[2]/div/p/a')
# 記事全文を読むボタンをクリック
search_btn.click()
time.sleep(2)
driver.find_element_by_xpath('//*[@id="uamods-pickup"]/div[2]/div/p/a')
でxpathで探し出した「記事全文を読む」の要素を格納し、
クリック処理を行っています。
xpathの探し方は↓になります。
・記事全文を読むにカーソルを当てる
・右クリック > 検証
・検証ツールからcopy > xpathをコピー

後の処理は先ほどと同じ要領で
・画面に表示されている内容をBeautifulSoupで解析
・欲しい情報を取得
するだけです。
情報を取得したらリスト関数へ追加していきます。
# 取得した内容をリスト変数へ書き込む
if detail is not None:
i = i + 1
title_detail.append([i,summary_soup.title.text,detail.text,detail_Url[0]["content"]])
ここまできたら、後はCSVへ出力して完成ですね!
今回も最後は駆け足気味となってしまいましたが、
SeleniumとBeautifulSoupを使用してYahooニュースの記事を取得することが出来ました。
BeautifulSoupだけでも出来たかと思いますが!
クリックイベントの処理などはSeleniumの方が分かり易いな。
と感じた内容でした。
以上です。
最後までお読みいただきありがとうございました!