【Selenium】implicitly_wait
行いたいこと Pythonのコードで、固定の秒数ではなく 「implicitly_wait」を使用して 要素が見つかるまでの待機時間を設定したいと思います。 今回はYoutubeを表示した際に、「野球」タブが表示されるま…
 Python
Python
行いたいこと Pythonのコードで、固定の秒数ではなく 「implicitly_wait」を使用して 要素が見つかるまでの待機時間を設定したいと思います。 今回はYoutubeを表示した際に、「野球」タブが表示されるま…
Python
行いたいこと 今回は稀に使用する「get_attribute」についてのメモです。 get_attributeを使用すると、属性の属性値を取得することが可能です。 下記で言うと属性を指定して、属性値を取得する。 属性:a…
Python
行いたいこと 今回はHTMLでのXpath指定をPythonで指定するメモを残したいと思います。 例えばHTMLで「//h1[@class=”_3cl937Zpn1ce8mDKd5kp7u”]」 と指定した場合にPyth…
Python
行いたいこと 以下のような画面で class=”form-check-input needs-calc” となっている場合の指定。 find_element_by_class_name(“form-check-input…
Python
Seleniumコピペ用 起動~操作時によく使用する処理をメモ用に残します。 ・ヘッドレスモードでの起動や、ウィンドウサイズの指定。 ・xpathやclassなどでクリックする処理など のメモ書きになります。 サイトはテ…
Python
行いたいこと Googleの検索結果を別タブで開いてみたいと思います。 実行結果は以下のイメージ。 コード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
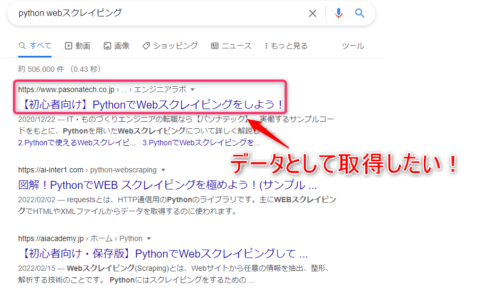
from bs4 import BeautifulSoup import time from selenium import webdriver driver = webdriver.Chrome("chromedriver_win32/chromedriver.exe") # 上位から何件までのサイトを抽出するか指定する pages_num = 3 # キーワード key_word = 'webスクレイピング' # Google検索で「webスクレイピング」の結果を格納する url = 'https://www.google.com/search?num={}&q={}'.format(pages_num,key_word) # URLを開く driver.get(url) time.sleep(3) # WebサイトのHTMLデータをBeautifulSoupで解析する soup = BeautifulSoup(driver.page_source,'html.parser') # 検索結果のまとまり page_titles = soup.find_all(class_="tF2Cxc") i = 1 # 1件別でURLを取得する for page_title in page_titles: url = page_title.find("a").get("href").replace('/url?q=','') print("url = " , url) # タブを右隣に新規追加 driver.execute_script("window.open()") # 操作対象のタブを追加したタブに設定 driver.switch_to.window(driver.window_handles[i]) # 検索結果から取得したURLへ遷移させる driver.get(url) # タブを右に追加していきたいので数字をプラスする i = i + 1 time.sleep(2) # 開き終わったら一番左のタブへ操作対象を戻す driver.switch_to.window(driver.window_handles[0]) |
解説 タブで開く前に、開く先のURLを取得して…
 Python
Python
XPath Helperとは XPath Helperは簡単にxpathを取得出来るChromeのツール。 らしいです。 これまでxpathをコピーする際は、 ・右クリック > 検証 > コピー > xpathをコピー …
 Python
Python
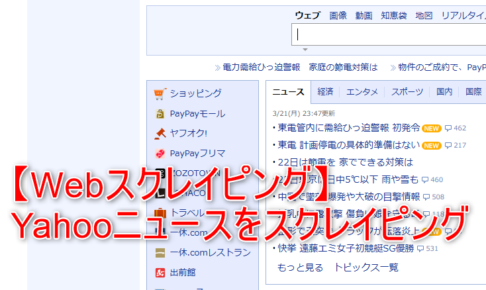
Yahooニュースのスクレイピング 今回はYahooニュースの「ニュース」タブの部分の取得、 それぞれのニュースの詳細(記事全文を読む)の部分を SeleniumとBeautifulSoupを使用して取得してみたいと思い…
 Python
Python
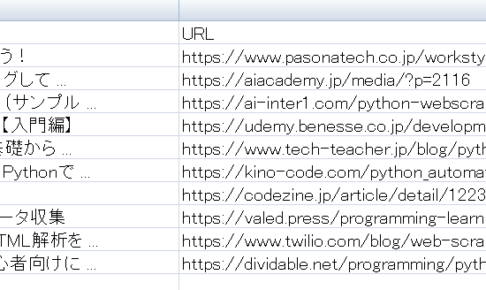
検索結果をCSVへ! 前回スクレイピングした内容をテキストへ保存しました! CSVへの保存も簡単に行えます。 前回のソースコードを少し綺麗に?しながらCSVファイルへ落とし込みたいと思います。 【イメージ】 ↓ の検索結…
 Python
Python
検索結果をスクレイピング 前回はメルカリのスクレイピングをSeleniumで行いました。 今回は「BeautifulSoup」を使ってみたいということで、 メルカリと比べると大分短いソースコードになりますが、 ・Goog…