Last Updated on 2025年7月28日
検索結果をスクレイピング
前回はメルカリのスクレイピングをSeleniumで行いました。

今回は「BeautifulSoup」を使ってみたいということで、
メルカリと比べると大分短いソースコードになりますが、
・Googleでキーワード検索 → 表示された結果をスクレイピング
を行いたいと思います。
早速ですが今回のコードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
from bs4 import BeautifulSoup import time # selenium関連 from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.chrome.options import Options # ヘッドレスモードを付与 options = Options() options.add_argument("--headless") driver = webdriver.Chrome(ChromeDriverManager().install(),options=options) # 上位から何件までのサイトを抽出するか指定する pages_num = 10 + 1 # キーワード key_word = 'python Webスクレイピング' # Google検索で「python Webスクレイピング」の結果を格納する url = 'https://www.google.com/search?num={}&q={}'.format(pages_num,key_word) # SeleniumでURLを起動する driver.get(url) time.sleep(2) # WebサイトのHTMLデータをBeautifulSoupで解析する soup = BeautifulSoup(driver.page_source,'html.parser') # 検索結果のまとまり page_titles = soup.find_all(class_="NJo7tc Z26q7c jGGQ5e") title_detail = [] i = 0 # 1件別でタイトルとURLを取得する for page_title in page_titles: title = page_title.h3.text url = page_title.find("a").get("href").replace('/url?q=','') i = i + 1 # 取得した内容をリスト変数へ書き込む title_detail.append([i,title,url]) # リスト → テキストへ書き込む前にStr型にする str_all_data = [str(x) for x in title_detail] # テキストへ書き込む処理 with open("Google_サーチ.txt", "w") as f: f.writelines('\n'.join(str_all_data)) |
Pyファイルを実行してもWebブラウザは起動しません!
もし動作を見ながら動かしたい場合は
14行目の「,options=options」
を削除してください。
解説
Googleの検索結果は
表示したい件数とキーワードを送信することで表示されています。
例えば「Python Webスクレイピング」
で検索したい場合のURLは以下のようになっています。
![]()
[num]の後に表示したい件数
[q]の後にキーワード。
をそれぞれ送信したら検索が行えます。
numの方ですが、どうやら件数-1件が検索結果となるようです。
なので10件表示したい場合は[11]の数を渡す必要があります。
上記を踏まえた上で、以下のコードになります。
[pages_num]は表示したい検索結果の件数
[key_word]は検索内容ですね。
|
1 2 3 4 5 6 7 8 |
# 上位から何件までのサイトを抽出するか指定する pages_num = 10 + 1 # キーワード key_word = 'python Webスクレイピング' # Google検索で「python Webスクレイピング」の結果を格納する url = 'https://www.google.com/search?num={}&q={}'.format(pages_num,key_word) |
今回表示したい件数は10件。
キーワードは「python Webスクレイピング」です。
[url]には、フォーマットを用いています。
1つ目の{}には表示する件数。
2つ目の{}にはキーワード。
がそれぞれ入ります。
driver.get
|
1 2 3 4 5 6 7 |
# SeleniumでURLを起動する driver.get(url) time.sleep(2) # WebサイトのHTMLデータをBeautifulSoupで解析する soup = BeautifulSoup(driver.page_source,'html.parser') |
SeleniumでURLを取得 → 表示。
表示されたWebサイトのHTMLをBeautifulSoupで解析。
を行っています。
なぜここでSeleniumを使用しているかと言いますと、
Javascriptが使用されているページ(Googleの検索結果)は
・requests.get(url)
・driver.get(url)
でChromeで検証ツールを用いた時と実行したときの要素が変わってしまうのですね!
詳しくは下記をご覧くださいませ。

取得するclass
|
1 2 |
# 検索結果のまとまり page_titles = soup.find_all(class_="NJo7tc Z26q7c jGGQ5e") |
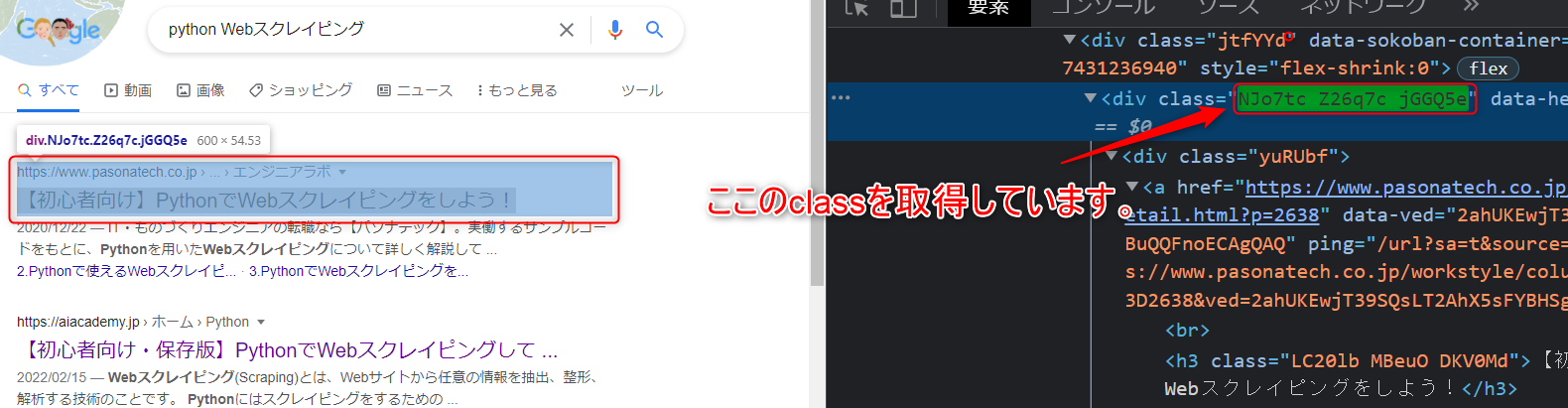
driver.getしないと、このclassの要素が実行時に見つかりません。
取得したデータの処理
欲しいのは、検索結果の
・順番
・タイトル
・URL
になります。
以下のコードの部分ですね。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# 1件別でタイトルとURLを取得する for page_title in page_titles: title = page_title.h3.text url = page_title.find("a").get("href").replace('/url?q=','') i = i + 1 # 取得した内容をリスト変数へ書き込む title_detail.append([i,title,url]) # リスト → テキストへ書き込む前にStr型にする str_all_data = [str(x) for x in title_detail] |
取得方法はいくつかあると思いますが、
・順番はforループで回す変数「i」で取得
・タイトルは「page_title.h3.text」でテキストのみを取得
・URLは「href」のみを取得
この時「href」属性は「/url?q=」という部分まで引っ張ってくるので、「replace」を使用して「/url?q=」は削除(空白へ置換)しています。
forの最後にはappendを使用して1行毎に「i,title,url」を追加していきます。
最後にテキストへと書き込みを行います。
しかしこの状態だとエラーになってしまうので
12行目でStr型へ変換しています。
テキストへ書き込む
ここはおなじみですね。
|
1 2 3 4 |
# テキストへ書き込む処理 with open("Google_サーチ.txt", "w") as f: f.writelines('\n'.join(str_all_data)) |
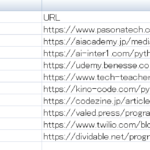
Googleサーチというテキストファイルを作成して、中にappendしたリストを書き込んでいます。
その時に1行ずつ改行して書き込むように改行コードをjoinしています。
出来上がったテキストファイルはこのような形となります。
※ 実際は10件表示されます。

今回も最後は駆け足気味!
とりあえずGoogleの検索結果も意外と簡単にスクレイピングが行えました。
テキストへの書き込みも良い感じですね。
今回は以上となります。
最後までお読み頂きありがとうございました!