Last Updated on 2025年7月28日
classが見つからない!
前回は「Selenium」のみのWebスクレイピングを行ったので
今回は「BeautifulSoup」を使用したいと思い、
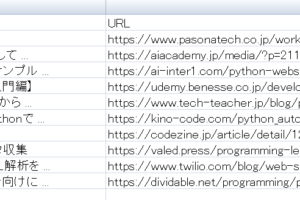
Googleの検索結果で以下のような1件ずつの
タイトルとURLを取得したいと思いました。
ということで検索結果後に
Chrome検証ツールから確認すると、こんな感じになります
class = "yuRUbf"

そこでBeautifulSoupにて、
下記のコードを実装。
|
1 |
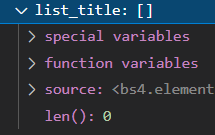
list_title = soup.find_all(class_="yuRUbf") |
しかし、実行してみるとなぜか中身が空なんです、、、
最初はホントになぜ?と思い調べてみると
javascriptが関係しているみたいでした。
いくつか対応方法がありましたが、下記を試してみようかと思います。
1.単純にjavascriptをオフにして検証ツールから確認する
2.Seleniumからpage_sourceを渡す
今回は1の方のjavascriptをオフにする方法です。
まずchromeのjavascriptをオフにします。
【javascriptオフの手順】
1. chromeの画面右上の三点リーダー > 設定をクリック
2. セキュリティとプライバシー > サイトの設定をクリック
3. 下へスクロールするとJavaScriptが表示されるのでクリック
4. 「サイトに JavaScript の使用を許可しない」を選択
→ 自動保存されます。
1. chromeの画面右上の三点リーダー > 設定をクリック
2. セキュリティとプライバシー > サイトの設定をクリック
3. 下へスクロールするとJavaScriptが表示されるのでクリック
4. 「サイトに JavaScript の使用を許可しない」を選択
→ 自動保存されます。
ずっとJavaScriptがオフだと何かと不便なので、
実装が終わったらオンにしたいと思いますw
オフにしてみて、再度検索結果から検証ツールを起動します。
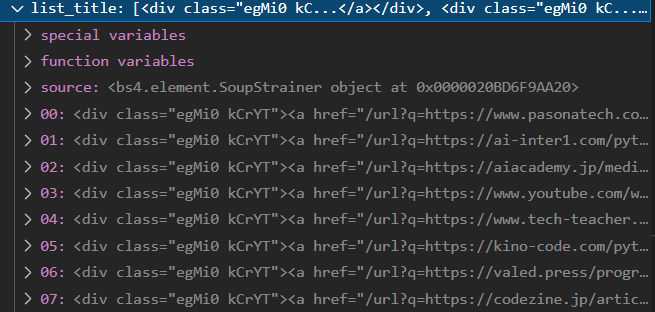
そしたらなんと

全然違いますね!!!
class = "egMi0 kCrYT"
改めて以下で実装です。
|
1 |
list_title = soup.find_all(class_="egMi0 kCrYT") |
すんなりと取得することが出来ました。
次回は「2.Seleniumからpage_sourceを渡す」を試してみたいと思います。
絶対にこっちの方が良さそうw
今回は以上となります。
最後までお読みいただき、ありがとうございました。