Last Updated on 2025年7月28日
今回行うこと
前回はメルカリを開いて検索して「新しい順」
でソートするまでを行いました。

今回は以下を行って完結です!
・表示された内容に対してタイトルや価格を取得する
・何件まで取得するかを確定する
・取得した内容をCSVに保存する
まず最初に完成したコードを記載します。
解説はコードの下で!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 |
from selenium import webdriver from time import sleep from selenium.webdriver.common.keys import Keys from selenium.webdriver.support.ui import Select # 以下を新規に追加する import csv import datetime import os import locale # /*------------------------------------------ # ドライバーの準備 # --------------------------------------------*/ def get_driver(): # chromeドライバーまでのパスを格納する driver = webdriver.Chrome("chromedriver_win32/chromedriver.exe") driver.maximize_window() # 固定の秒数ではなく、指定した要素が見つかるまでの待ち時間を設定 driver.implicitly_wait(5) return driver # /*------------------------------------------ # メルカリのURLを取得する # --------------------------------------------*/ def get_top_page(driver): # メルカリのトップページを表示する driver.get("https://jp.mercari.com/") driver.implicitly_wait(5) # 検索フォームxpathを格納する search_bar = driver.find_element_by_xpath('//*[@id="gatsby-focus-wrapper"]/div/div/header/mer-navigation-top/mer-autocomplete/div[1]/mer-search-input') driver.implicitly_wait(5) # 検索ボックスにキーワードを格納する search_key = "python 本" search_bar.send_keys(search_key) driver.implicitly_wait(5) # キーワードを入力したらエンターキーで検索を行う search_bar.send_keys(Keys.ENTER) # 新しい順番に並び替える new_sort = driver.find_element_by_xpath("//*[@id='search-result']/div/div/section[1]/div/div[2]/div/label/mer-select/div/div[1]/select[1]") select_new_sort = Select(new_sort) select_new_sort.select_by_visible_text("新しい順") # 現在のhtml情報を格納する page_source = driver.page_source # html情報と検索したキーワードを返す return search_key # /*------------------------------------------ # メルカリのページからスクレイピングを行う # --------------------------------------------*/ def get_data_from_source(search_key): # xpath変数の準備 # 記事一覧取得(キーワードに引っかかった数) pd_xpath = "//li[contains(@data-testid, 'item-cell')]/a" numbers = driver.find_elements_by_xpath(pd_xpath) pd_lists = [number.get_attribute('href') for number in numbers] # タイトルのxpath格納 pd_title_xpath = '//*[@id="item-info"]/section[1]/div[1]/mer-heading' # 金額のxpath格納 pd_price_xpath = '//*[@id="item-info"]/section[1]/section[1]/div/mer-price' # 商品情報を格納するリスト pd_detail = [] driver.implicitly_wait(5) # 商品情報を格納するリスト pd_detail = [] # 商品個別ページを表示 pd_no = 1 for pd_list in pd_lists: try: # 商品ページ詳細のURLを渡す driver.get(pd_list) driver.implicitly_wait(5) # 1商品のタイトル pd_name = driver.find_element_by_xpath(pd_title_xpath).get_attribute("title-label") # 1商品の料金 pd_price = driver.find_element_by_xpath(pd_price_xpath).get_attribute("value") # 1商品の詳細ページのURL pd_url = driver.current_url # 取得した情報を1行単位で追加する pd_detail.append([pd_no,search_key, pd_name, pd_price, pd_url]) # 待機処理 sleep(2) pd_no = pd_no + 1 # 3件まで抽出する。4件になったら抜ける if pd_no > 3: break except: break save_csv(pd_detail) # /*------------------------------------------ # CSVファイルの処理 # --------------------------------------------*/ def save_csv(pd_detail): # ファイルを実行している場所に格納する file_path = os.getcwd() print("file_path = " + file_path) locale.setlocale(locale.LC_ALL, '') csv_date = datetime.datetime.today().strftime("%Y%m%d_%H" + "時" + "%M" + "分" + "%S" + "秒") # 相対パスで実行ファイルのフォルダ内のCSVフォルダへCSVを作成して格納する csv_path = os.getcwd() csv_file_name = "Merkari_" + csv_date + ".csv" # ファイルを格納する場所、ファイル名 csv_path = os.path.join(csv_path,csv_file_name) with open(csv_path, 'w') as file: writer = csv.writer(file, lineterminator='\n') # CSVファイルの1行目 csv_header = ["掲載No","検索キーワード","商品名","金額","商品URL"] # 最初に1行目を書き込む writer.writerow(csv_header) # pd_detailには1行ずつ商品の情報が格納されている writer.writerows(pd_detail) # /*------------------------------------------ # main処理 # --------------------------------------------*/ if __name__ == "__main__": # ブラウザのdriver取得 driver = get_driver() # ページのソース取得 search_key = get_top_page(driver) # 新しい順でソートしたhtml情報をスクレイピングする get_data_from_source(search_key) |
表示された内容に対してタイトルや価格を取得する
ここから解説です。
main処理で以下を追加しています。
# 新しい順でソートしたhtml情報をスクレイピングする
get_data_from_source(search_key)
引数で渡している変数
・search_key:検索キーワード
となっています。
その引数を「get_data_from_source」へ渡しています。
def get_data_from_source(search_key)
get_data_from_source関数では
最初に変数を格納しています。
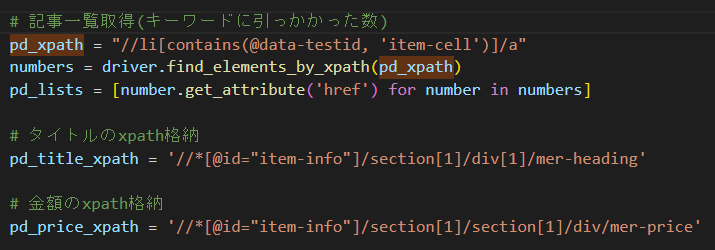
最初に検索したキーワードで引っかかった件数(1ページ目)を取得しています。
これは画面上の件数「999+件」ではなく、
1ページ目に表示されている120件それぞれになります。

今までは単純に要素に対して右クリック > 検証 > xpathのコピーを行っていましたが、
今回のように1ページ目に表示されている件数を取得したい場合はxpathを自分で考える必要があります。
xpathが「//li[contains(@data-testid, 'item-cell')]/a」
というのは、
ページ内に表示されている「liタグの中に、de-ta-testid=item-cellの要素からaタグを取得する」
という意味になります。
※ 詳しくは「スクレイピング xpath」などで検索すると解説してくれるサイトが多く表示されるかと思います。
pd_lists = [number.get_attribute('href') for number in numbers]
としている箇所は、「numbers」にはaタグが返ってきていますので
aタグの中にあるhref要素。
つまり詳細ページへのリンクがpd_listsに格納されていきます。
pd_listsをforで回せば、それぞれ詳細ページ飛ぶ。
という流れですね。
詳細ページでは、以下のようにタイトルと料金を取得しています。
タイトルと料金を前回同様に
右クリック > 検証 > xpathをコピーしています。
・pd_title_xpath
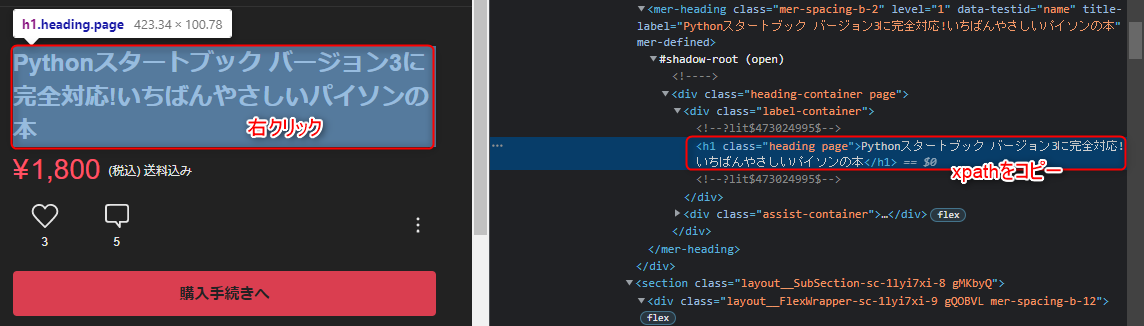
・pd_price_xpath
ここは注意が必要です。
「1800」のように料金の項目に
カーソルを当て、右クリック > 検証
を行った場合に上手く取得が出来ません。
画像を参考に、検証ツールで少し上の階層のxpathを取得してあげてください。

取得したhrefのURLより、forで1件1件詳細ページに飛んでいます。
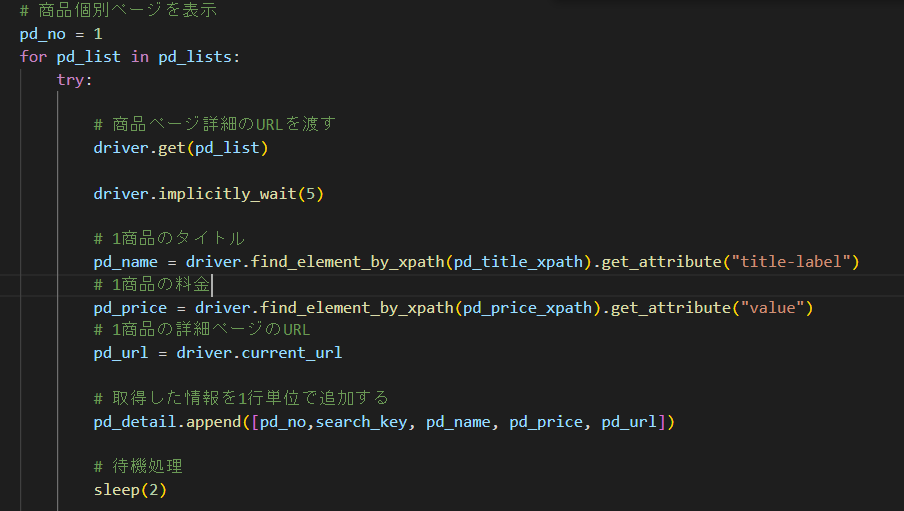
タイトルや料金をそれぞれ格納した後、
urlは、既に詳細ページに入っている状態なので、crrent_urlで取得します。
pd_detail.append([pd_no,search_key, pd_name, pd_price, pd_url])
については、後でcsvファイルに書き込むため、リストに格納していきます。
今回は取得していませんが、詳細ページに記載されている
・カテゴリー
・商品の状態
・配送料の負担
などもxpathのコピーから簡単にスクレイピングが行えるかと思います。
件数を何件取得するかは、以下の処理です。
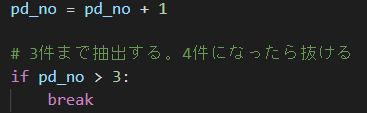
pd_noは1から始まっているので、4件目が来たらループ終了です。
最後に
save_csv(pd_detail)
でcsvファイルに書き出して完了となります。
def save_csv(pd_detail)
ここは凄く単純です。
流れは以下の通りとなります。
・csvファイルを格納するpathを定義する
・csvファイルへ日付をファイル名に使用したいのでdetetime関数を使用する
・相対パスで格納するpathとファイル名を確定させる
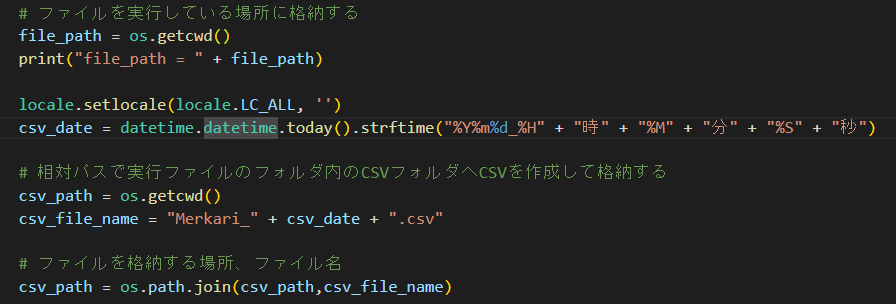
・open関数を使用してcsvファイルの書き込みを行う
・csvは最初にヘッダー部分を固定の文字列で書き込む
・続いてappendしたリストの内容を書き込む
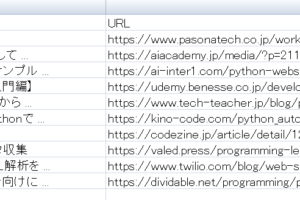
プログラムを実行し、以下のcsvファイルが出力されていたら完成です。

最後の方は大分駆け足になってしまいました!
そして「BeautifulSoup」は使用しなかった、、、w
次はBeautifulSoupを使用したスクレイピング記事を作成したいところです。
メルカリのページはxpathが適宜更新されるようですので、
上手く動作しない場合は要素の取得を最新のものに書き換えて実行してみてください!
最後までお読みくださり、どうもありがとうございました。