Last Updated on 2025年7月28日
Webスクレイピングとは
この記事をご覧になってくださる方は既にご存じかと思いますが、
Webスクレイピングとは、Webサイトから自分が必要な情報を収集できる。
ことだと考えています(ザックリ)
例えば
・グーグルの検索結果で上位10位までの検索結果をリサーチ
・求人サイトで自分好みの絞り込みを行った結果を入手
などなどが行えたり、
もちろん実行結果をターミナルに出力するだけでなく
CSVファイルに保存したりといったことも可能です。
他にも検索した結果が前回と異なっていればLINEに通知など出来れば
本格的な自動化。といえそうですね!
今回は
・メルカリで自分が検索したキーワードで絞り込んだ結果を出力する
までの内容を記事にしたいと思います。
長くなりそうなので、何回かに分けて、、、
Webスクレイピングを始める前に
私自身、最近自動化に興味を持ったので
Webサイトの情報を取得したいなと思うようになりました。
Webスクレイピングに興味を持ったのは良いですが、
いくつか注意点が存在していますので個人でWebスクレイピングを行う際は、
先に「Webスクレイピング 注意事項」などで検索、閲覧してからコードを実行した方が良さそうですね。
色々な注意や解釈がされていますが、下記の記事など凄く参考になります。
Webスクレイピングの注意事項一覧
今回の環境
これからコードを書く前に
・OS:Windows10 64bit
・Webブラウザ:Chrome
・VSCode:インストール済み
・Python:インストール済み
上記を前提として内容を書いていこうと思います。
VSCode上でPythonを実行したことのある人なら問題ないかと思います。
SeleniumやBeautifulsoup4を使用しますので未インストールの方は
■ Seleniumのインストールコマンド
pip install selenium
■ Beautifulsoup4のインストールコマンド
BeautifulSoup
にてインストールを行ってください。
Webドライバーのダウンロード
またSeleniumはWebドライバーを必要としていますので、
下記の手順でインストールを行います。
WebドライバーはChromeのバージョンによってダウンロードするバージョンが異なります。
ので、自身のChromeバージョンに近いものをダウンロードしてください。
OSがWindows64bit版の方もWebドライバーは32bit版をダウンロードで問題ありません。
1. Chromeを起動し、バージョンを確認する
Chromeの右上、メニューボタンをクリック > ヘルプ > Google Chromeについて をクリック

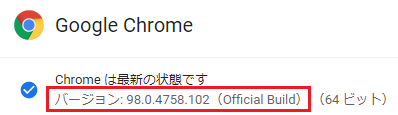
2. Webドライバーのバージョンを確認する(例では98.0.4758.102)
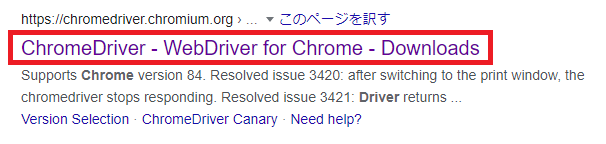
3. WebドライバーをGoogle検索して、下記のサイトをクリックする
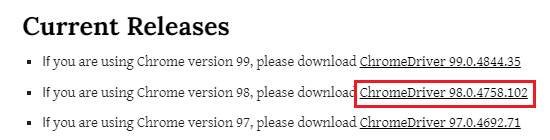
4. 自分のChromeのバージョンに近い番号をクリックする
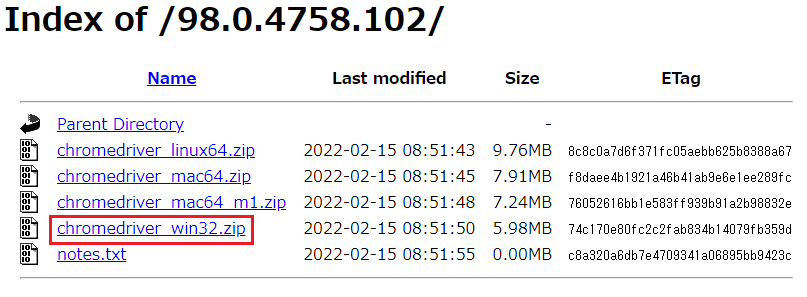
5. サイト上からWebドライバーをダウンロードする
6. 任意の場所に保存して解凍する
解凍した中身に「chromedriver.exe」が入っていたら完了です。
今回の例では、
.pyファイルと同階層に「chromedriver_win32.zip」を解凍しています。
続いてコードを書いていきます。
まずは今ダウンロードしてきたWebドライバーを使用して
・メルカリのトップページを開く。
までを行います。
メルカリのトップページを表示
以下の内容を「Mercari_WebScraping.py」として保存し
実行してみるとメルカリのトップページが開いて、5秒後にChromeが閉じられると思います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from selenium import webdriver from time import sleep # /*------------------------------------------ # メルカリのトップページを表示するだけ # --------------------------------------------*/ # Winなので、chromeドライバーまでのパスを格納する driver = webdriver.Chrome("chromedriver_win32/chromedriver.exe") # メルカリのトップページを表示する driver.get("https://jp.mercari.com/") # トップページを開いて5秒後にWebブラウザを閉じる sleep(5) |
実際にWebページが開くとワクワクしますね!
次回からは開いたメルカリのページに対してスクレイピングを行い、データ収集を行っていきたいと思います。
第2回の記事を公開しました。

最後までお読み頂き、ありがとうございました。






